【注意】最后更新于 May 7, 2023,文中内容可能已过时,请谨慎使用。
注:本文代码基于Android Sv2
一、概述
XML文件在Android中是一种非常常见的文件格式,例如你的主页面布局文件activity_main.xml、Android清单文件AndroidManifest.xml、XXX.xml的res资源文件等等,然而我们在日常开发中往往会忽略XML文件本身,因为AS太过智能化,根据AS智能提示很容易就能写出想要的XML文件,但是我们真的有了解过XML文件吗?还有为什么要去了解XML文件?阅读本文后,你应该可以找到问题的答案。
因此,本文会把关注点放到XML文件本身,学习它的基础语法,然后循序渐进地讲解Android中怎么解析XML数据,这对之后在Framework层遇到XML解析流程时非常有帮助,比如Activity的setContentView源码里,它是如何将我们写的layout布局文件解析出来的。
二、XML简单介绍
2.1、什么是XML?
XML的全称为Extensible Markup Language,翻译过来是可扩展标记语言,它是标准通用标记语言的子集,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。
2.2、XML的基本语法
2.2.1、必须有声明语句
XML声明是XML文档的第一句,代码如下:
1
|
<?xml version="1.0" encoding="UTF-8" ?>
|
2.2.2、XML文档有且只有一个根元素
良好格式的XML文档必须有一个根元素,就是紧接着声明后面建立的第一个元素,其他元素都是这个根元素的子元素,根元素完全包括文档中其他所有的元素,根元素的起始标记要放在所有其他元素的起始标记之前;根元素的结束标记要放在所有其他元素的结束标记之后,代码如下:
1
2
3
4
|
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<element></element>
</root>
|
在上面代码中,root称为根元素。
2.2.3、XML标签对大小写敏感
在XML文档中,大小写是有区别的,例如下面代码中“a”和“A”是不同的标记。注意在写元素时,前后标记的大小写要保持一致。最好养成一种习惯,或者全部大写,或者全部小写,或者大写第一个字母,这样可以减少因为大小写不匹配而产生的文档错误。
1
2
3
4
5
|
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<a></a>
<A></A>
</root>
|
2.2.4、属性值必须加引号
XML规定,所有属性值必须加引号(可以是单引号,也可以是双引号,建议使用双引号),否则将被视为错误。
如下代码为错误演示:
1
2
3
4
5
|
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<!--IDE报错-->
<element id=999></element>
</root>
|
如下代码为正确演示:
1
2
3
4
|
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<element id="999"></element>
</root>
|
2.2.5、所有的标记必须有相应的结束标记
在XML中,所有标记必须成对出现,有一个开始标记,就必须有一个结束标记,否则将被视为错误。
2.2.6、实体引用
在XML中,一些字符拥有特殊的意义,如果你把字符"<“放在XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。
1
2
3
4
5
|
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<!--IDE报错-->
<count>num < 1000</count>
</root>
|
为了避免这个错误,需要用实体引用来代替”<“字符。
1
2
3
4
|
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<count>num < 1000</count>
</root>
|
在XML中,有5个预定义的实体引用。
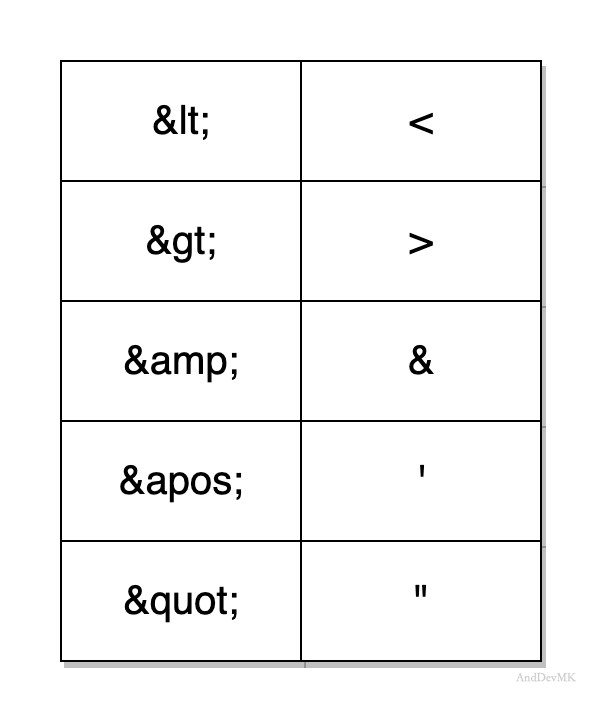
2.2.7、命名空间
在XML中,因为元素名称是由开发者定义的,当两个不同的文档使用相同的元素名时,就会发生命名冲突。
这个XML文档在表格中记载着学生信息。
1
2
3
4
5
6
7
8
9
10
|
<table>
<tr>
<td>Tony</td>
<td>202323</td>
</tr>
<tr>
<td>Jerry</td>
<td>202324</td>
</tr>
</table>
|
这个XML文档记载着个人信息。
1
2
3
4
5
|
<table>
<name>Tony</name>
<weight>65</weight>
<height>175</height>
</table>
|
假如这两个XML文档被一起使用,由于两个文档都包含带有不同内容和定义的table元素,就会发生命名冲突,XML解析器无法确定如何处理这类冲突。
如果以Java的思维来描述,可以认为是在同一个包下,创建了两个类名都为Table的类,那么在使用时就会不知道要用的是哪个了。
因此,需要用XML命名空间来解决该冲突问题。XML命名空间属性被放置于元素的开始标签之中,其语法为:
1
|
xmlns:namespace-prefix="namespaceURI"
|
当XML命名空间被定义在元素的开始标签中时,所有带有相同前缀的子元素都会与同一个命名空间相关联。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<root>
<s:table xmlns:s="https://www.student.com/">
<s:tr>
<s:td>Tony</s:td>
<s:td>202323</s:td>
</s:tr>
<s:tr>
<s:td>Jerry</s:td>
<s:td>202324</s:td>
</s:tr>
</s:table>
<p:table xmlns:p="https://www.person.com/">
<p:name>Tony</p:name>
<p:weight>65</p:weight>
<p:height>175</p:height>
</p:table>
</root>
|
命名空间也可以在XML根元素中声明。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<root xmlns:s="https://www.student.com/"
xmlns:p="https://www.person.com/">
<s:table>
<s:tr>
<s:td>Tony</s:td>
<s:td>202323</s:td>
</s:tr>
<s:tr>
<s:td>Jerry</s:td>
<s:td>202324</s:td>
</s:tr>
</s:table>
<p:table>
<p:name>Tony</p:name>
<p:weight>65</p:weight>
<p:height>175</p:height>
</p:table>
</root>
|
为元素定义默认的命名空间可以让我们省去在所有的子元素中使用前缀的工作,其语法为:
这个XML文档在表格中记载着学生信息。
1
2
3
4
5
6
7
8
9
10
|
<table xmlns="https://www.student.com/">
<tr>
<td>Tony</td>
<td>202323</td>
</tr>
<tr>
<td>Jerry</td>
<td>202324</td>
</tr>
</table>
|
这个XML文档记载着个人信息。
1
2
3
4
5
|
<table xmlns="https://www.person.com/">
<name>Tony</name>
<weight>65</weight>
<height>175</height>
</table>
|
三、Android解析XML数据
3.1、选择XML解释器
Android提供了三种类型的XML解析器,它们是DOM、SAX和XmlPullParser,但是官方建议使用XmlPullParser,这是一种在Android上解析XML的高效且可维护的方式,Android有此接口的两个实现如下:
- KXmlParser,使用XmlPullParserFactory.newPullParser()
- ExpatPullParser,使用Xml.newPullParser()
上面两种任一选择都可以,在本文的示例中使用的是ExpatPullParser和Xml.newPullParser()。
3.1.1、XmlPullParser接口
这里仅列举XmlPullParser接口和后面示例有联系的变量和方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
public interface XmlPullParser {
// ***************next()报告的事件类型***************
// 表明解析器位于文档的最开头,尚未读取任何内容,这种事件类型只能通过在第一次调用next()、nextToken或nextTag()之前调用getEventType()来观察
int START_DOCUMENT = 0;
// xml文档的逻辑结束,当到达输入文档的末尾时,从getEventType()、next()和nextToken()返回
int END_DOCUMENT = 1;
// 读取开始标记时从getEventType()、next()、nextToken()返回。开始标记的名称可从getName()获得,其命名空间和前缀可从getNamespace()和getPrefix()获得(如果命名空间已启用)
int START_TAG = 2;
// 读取结束标记时从getEventType()、next()或nextToken()返回。开始标记的名称可从getName()获得,其命名空间和前缀可从getNamespace()和getPrefix()获得
int END_TAG = 3;
// 已读取字符数据并将通过调用getText()获得
int TEXT = 4;
// 该数组可用于将事件类型整型常量(如START_TAG或TEXT)转换为字符串。例如,TYPES[START_TAG]的值是字符串“START_TAG”。该数组仅用于诊断输出。依赖数组的内容可能是危险的,因为恶意应用程序可能会更改数组,尽管它是最终的,但由于Java语言的限制
String [] TYPES = {
"START_DOCUMENT",
"END_DOCUMENT",
"START_TAG",
"END_TAG",
"TEXT",
"CDSECT",
"ENTITY_REF",
"IGNORABLE_WHITESPACE",
"PROCESSING_INSTRUCTION",
"COMMENT",
"DOCDECL"
};
// ***************命名空间相关特性***************
// 这个特性决定了解析器是否处理命名空间。对于所有功能,默认值为false
// 注意:该值在解析期间不能更改,必须在解析前设置
String FEATURE_PROCESS_NAMESPACES =
"http://xmlpull.org/v1/doc/features.html#process-namespaces";
// 使用此调用来更改解析器的一般行为,例如命名空间处理或文档类型声明处理。必须在第一次调用next或nextToken之前调用此方法。否则,将抛出异常
void setFeature(String name,
boolean state) throws XmlPullParserException;
// 将解析器的输入源设置为给定的阅读器并重置解析器。事件类型设置为初始值 START_DOCUMENT。将读取器设置为null只会停止解析并重置解析器状态,从而允许解析器释放解析缓冲区等内部资源
void setInput(Reader in) throws XmlPullParserException;
// 设置解析器将要处理的输入流。此调用重置解析器状态并将事件类型设置为初始值START_DOCUMENT
// 注意:如果传递了输入编码字符串,则必须使用它。否则,如果inputEncoding为null,解析器应该尝试确定遵循XML 1.0规范的输入编码(见下文)
void setInput(InputStream inputStream, String inputEncoding)
throws XmlPullParserException;
// ***************TEXT相关方法***************
// 检查当前TEXT事件是否只包含空白字符。对于IGNORABLE_WHITESPACE,这始终为真。对于TEXT和CDSECT,当当前事件文本至少包含一个非空白字符时返回false。对于任何其他事件类型,都会抛出异常
boolean isWhitespace() throws XmlPullParserException;
// 以String形式返回当前事件的文本内容。返回值取决于当前事件类型,例如对于TEXT事件,它是元素内容(这是使用next()时的典型情况)
String getText ();
// ***************START_TAG END_TAG共享方法***************
// 对于START_TAG或END_TAG事件,启用命名空间时返回当前元素的(本地)名称。当命名空间处理被禁用时,原始名称被返回。对于ENTITY_REF事件,返回实体名称。如果当前事件不是START_TAG、END_TAG或ENTITY_REF,则返回null
String getName();
// ***************START_TAG属性检索方法***************
// 返回由命名空间URI和命名空间localName标识的属性值。如果命名空间被禁用,命名空间必须为空。如果当前事件类型不是START_TAG,则将抛出IndexOutOfBoundsException
String getAttributeValue(String namespace,
String name);
// ***************实际解析方法***************
// 返回当前事件的类型(START_TAG、END_TAG、TEXT等)
int getEventType()
throws XmlPullParserException;
// 获取下一个解析事件 - 元素内容将被合并,并且必须为整个元素内容只返回一个TEXT事件(将忽略注释和处理指令,并且必须扩展实体引用,或者如果实体引用无法扩展则必须抛出异常)。如果元素内容为空(内容为“”),则不会报告TEXT事件
int next()
throws XmlPullParserException, IOException;
// ***************使XML解析更容易的实用方法***************
// 测试当前事件是否属于给定类型以及命名空间和名称是否匹配。null将匹配任何名称空间和任何名称。如果测试未通过,则抛出异常。异常文本表示解析器位置、预期事件和不符合要求的当前事件
void require(int type, String namespace, String name)
throws XmlPullParserException, IOException;
// 如果是START_TAG或END_TAG,则调用next()并返回事件,否则抛出异常。如果有的话,它将跳过实际标记之前的空白TEXT
int nextTag() throws XmlPullParserException, IOException;
}
|
接下来,只讲解一下重点的方法。
3.1.1.1、next方法
从上面的注释可以知道,next方法用于获取下一个解析事件,但是它有一些现象需要知道下。
- 现象一:如果元素内容为空,则不会报告TEXT事件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// kotlin原始字符串
val xml = """
<school></school>
""".trimIndent()
val parser = Xml.newPullParser()
// 解析器不处理命名空间
parser.setFeature(XmlPullParser.FEATURE_PROCESS_NAMESPACES, false)
parser.setInput(StringReader(xml))
var eventType = parser.eventType
while (eventType != XmlPullParser.END_DOCUMENT) {
Log.e("MinKin", "eventType: ${XmlPullParser.TYPES[eventType]}; name: ${parser.name}; text: ${parser.text}")
eventType = parser.next()
}
|
打印结果如下:
1
2
3
|
E/MinKin: eventType: START_DOCUMENT; name: null; text: null
E/MinKin: eventType: START_TAG; name: school; text: null
E/MinKin: eventType: END_TAG; name: school; text: null
|
从打印结果来看,school元素内容为空时,的确没有触发TEXT事件。
不知到你们是否留意到,为什么也没有触发END_DOCUMENT事件?
其实是有触发的,只是不满足条件没法打印出来。因为While循环的判断条件为eventType != XmlPullParser.END_DOCUMENT,当eventType == XmlPullParser.END_DOCUMENT时,此时早已退出循环了,所以没有打印出来。
将上面代码中的xml变量替换为如下代码:
1
2
3
|
val xml = """
<school> < </school>
""".trimIndent()
|
此时因为school标签之间多了”<",运行时会触发XmlPullParserException这样的一个崩溃。把字符"<“放在 XML元素中,会发生错误,这是因为解析器会把它当作新元素的开始,为了避免这个错误,用实体引用来代替”<“字符,这也是我们之前讲过的。
1
2
3
|
val xml = """
<school> < </school>
""".trimIndent()
|
修改为实体引用后,打印结果如下:
1
2
3
4
|
E/MinKin: eventType: START_DOCUMENT; name: null; text: null
E/MinKin: eventType: START_TAG; name: school; text: null
E/MinKin: eventType: TEXT; name: null; text: <
E/MinKin: eventType: END_TAG; name: school; text: null
|
- 特性三:标签之间不是黏连一起的,比如之间有空格,或者出现了换行,或者存在子标签的情况下,都会报告TEXT事件。
将上面代码中的xml变量替换为如下代码:
1
2
3
4
|
// 标签之间有空格
val xml = """
<school> </school>
""".trimIndent()
|
1
2
3
4
5
|
// 标签之间出现了换行
val xml = """
<school>
</school>
""".trimIndent()
|
打印结果如下:
1
2
3
4
|
E/MinKin: eventType: START_DOCUMENT; name: null; text: null
E/MinKin: eventType: START_TAG; name: school; text: null
E/MinKin: eventType: TEXT; name: null; text:
E/MinKin: eventType: END_TAG; name: school; text: null
|
明显可以看到,这里school标签之间多打印了一次TEXT事件。如果是存在子标签的情况下,代码如下:
1
2
3
4
5
|
val xml = """
<school>
<count>1000</count>
</school>
""".trimIndent()
|
打印结果如下:
1
2
3
4
5
6
7
8
9
|
E/MinKin: eventType: START_DOCUMENT; name: null; text: null
E/MinKin: eventType: START_TAG; name: school; text: null
E/MinKin: eventType: TEXT; name: null; text:
E/MinKin: eventType: START_TAG; name: count; text: null
E/MinKin: eventType: TEXT; name: null; text: 1000
E/MinKin: eventType: END_TAG; name: count; text: null
E/MinKin: eventType: TEXT; name: null; text:
E/MinKin: eventType: END_TAG; name: school; text: null
|
明显可以看到,这里count标签前后多打印了两次TEXT事件。
3.1.1.2、nextTag方法
如果当前事件不是START_TAG或END_TAG,会抛出XmlPullParserException异常,例如下面代码就会崩溃。
1
2
3
4
5
6
7
8
9
10
11
|
val xml = """
<school>清华大学</school>
""".trimIndent()
val parser = Xml.newPullParser()
// 解析器不处理命名空间
parser.setFeature(XmlPullParser.FEATURE_PROCESS_NAMESPACES, false)
parser.setInput(StringReader(xml))
parser.next()
parser.nextTag()
|
分析原因:初始时,当前事件为START_DOCUMENT,调用parser的next方法后,事件变为START_TAG,然后再调用parser的nextTag方法时,它的事件状态应该不满足START_TAG或END_TAG,从而抛出了异常。
为什么不满足?nextTag方法本质源码为:
1
2
3
4
5
6
7
8
|
int eventType = next();
if(eventType == TEXT && isWhitespace()) { // skip whitespace
eventType = next();
}
if (eventType != START_TAG && eventType != END_TAG) {
throw new XmlPullParserException("expected start or end tag", this, null);
}
return eventType;
|
可以看到,会优先调用next方法,此时当前事件为TEXT,接着会去判断eventType == TEXT && isWhitespace(),但是isWhitespace方法是不满足的,因为school标签中存在元素内容“清华大学”,所以isWhitespace方法返回false,也就无法进入if条件去进一步调用next,事件停留在TEXT,满足了后面的eventType != START_TAG && eventType != END_TAG,从而抛出了异常。
注意:next方法和nextTag方法需要在合理的地方使用,使用不当就会抛出异常。
3.2、分析animal
创建一个animal.xml文件,解析animal的第一步是确定感兴趣的字段,解析器会提取这些字段的数据,并忽略其余字段。本案例会演示如何忽略cat标签,仅提取需要的字段。
要解析的XML内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
<?xml version="1.0" encoding="UTF-8" ?>
<animal xmlns="https://www.baidu.com/">
<dog>
<name>Rufus</name>
<breed>labrador</breed>
<link href="https://www.baidu.com/s?wd=labrador" rel="alternate"></link>
<profile type="html">
<![CDATA[
<p style="color: #34495e;">拉布拉多猎犬(英文名:Labrador retriever)是起源于加拿大的纽芬兰岛,最早被训练在冰冷的海上将渔网收回和担任搬运工作的一种猎犬。</p>
]]>
</profile>
</dog>
<dog>
<name>Marty</name>
<breed>whippet</breed>
<link href="https://www.baidu.com/s?wd=whippet" rel="alternate"></link>
<profile type="html">
<![CDATA[
<p style="color: #34495e;">小灵狗是一种赛狗,性温顺。和蔼。</p>
]]>
</profile>
</dog>
<cat>
<name>大黄</name>
</cat>
</animal>
|
习惯性,animal标签包含了命名空间xmlns,profile标签的元素内容标记为HTML,所以要把HTML内容当成整体的纯文本去提取,这里给HTML内容包裹一层<![CDATA[ HTML内容 ]],否则HTML中的标签会被XML当成元素去解析。
3.3、实例化XML解释器
解析animal的下一步就是实例化解析器和启动解析的过程,此代码段会初始化一个解析器,使其不处理命名空间并将提供的InputStream用作输入,它通过调用nextTag方法开始解析过程,并调用readAnimal方法,该方法将提取并处理应用感兴趣的数据,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class AnimalXMLParser {
// 不使用命名空间
private val ns: String? = null
@Throws(XmlPullParserException::class, IOException::class)
fun parse(inputStream: InputStream): List<Dog> {
inputStream.use {
val parser = Xml.newPullParser()
// 解析器不处理命名空间
parser.setFeature(XmlPullParser.FEATURE_PROCESS_NAMESPACES, false)
parser.setInput(it, null)
parser.nextTag()
return readAnimal(parser)
}
}
// ...
}
|
3.4、读取animal
readAnimal方法执行处理animal的实际工作,它会查找标记为“dog”的元素作为以递归方式处理animal的起点,如果某个标签不是dog标签,则会跳过它,以递归方式处理完整个animal后,readAnimal方法将返回结果集List,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
@Throws(XmlPullParserException::class, IOException::class)
private fun readAnimal(parser: XmlPullParser): List<Dog> {
val dogs = mutableListOf<Dog>()
// 测试当前事件是否属于给定类型以及命名空间和名称是否匹配
parser.require(XmlPullParser.START_TAG, ns, "animal")
while (parser.next() != XmlPullParser.END_TAG) {
if (parser.eventType != XmlPullParser.START_TAG) {
continue
}
if (parser.name == "dog") {
dogs.add(readDog(parser))
}
else {
skip(parser)
}
}
parser.require(XmlPullParser.END_TAG, ns, "animal")
return dogs
}
|
其中Dog类为:
1
2
3
4
5
6
|
data class Dog(
val name: String?,
val breed: String?,
val link: String?,
val profile: String?
)
|
3.5、解析XML
解析XML animal的步骤如下:
-
按照分析animal中所述,确定希望包含在应用中的标签。此示例提取了dog标签及其嵌套标签name、breed、link和profile的数据。
-
创建以下方法:
- 要包含的每个标签的“read”方法,例如readDog方法。解析器会从输入流中读取标签。当遇到此示例中名为name、breed、link和profile的标签时,它会调用该标签的相应方法。否则,它会跳过该标签。
- 为每个不同类型的标签提取数据并推动解析器解析下一个标签的方法。在此示例中,相关方法如下所示:
- 对于name、breed和profile标签,解析器会调用 readText方法。此方法通过调用parser的getText方法提取这些标签的数据。
- 对于link标签,解析器首先会确定链接是否为其感兴趣的类型,再提取该链接的数据。然后使用parser的getAttributeValue方法提取该链接的值。
- 对于dog标签,解析器会调用readDog方法。此方法会解析条目的嵌套标签,并返回包含数据成员name、breed、link和profile的Dog对象。
- 一种递归的辅助skip方法。
以下代码段展示了解析器如何解析name、breed、link和profile。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
@Throws(XmlPullParserException::class, IOException::class)
private fun readDog(parser: XmlPullParser): Dog {
parser.require(XmlPullParser.START_TAG, ns, "dog")
var name: String? = null
var breed: String? = null
var link: String? = null
var profile: String? = null
while (parser.next() != XmlPullParser.END_TAG) {
if (parser.eventType != XmlPullParser.START_TAG) {
continue
}
when (parser.name) {
"name" -> name = readName(parser)
"breed" -> breed = readBreed(parser)
"link" -> link = readLink(parser)
"profile" -> profile = readProfile(parser)
else -> skip(parser)
}
}
return Dog(name, breed, link, profile)
}
@Throws(XmlPullParserException::class, IOException::class)
private fun readProfile(parser: XmlPullParser): String {
parser.require(XmlPullParser.START_TAG, ns, "profile")
val profile = readText(parser)
parser.require(XmlPullParser.END_TAG, ns, "profile")
return profile
}
@Throws(XmlPullParserException::class, IOException::class)
private fun readLink(parser: XmlPullParser): String {
var link = ""
parser.require(XmlPullParser.START_TAG, ns, "link")
val tag = parser.name
val relType = parser.getAttributeValue(null, "rel")
if (tag == "link") {
if (relType == "alternate") {
link = parser.getAttributeValue(null, "href")
parser.nextTag()
}
}
parser.require(XmlPullParser.END_TAG, ns, "link")
return link
}
@Throws(XmlPullParserException::class, IOException::class)
private fun readBreed(parser: XmlPullParser): String {
parser.require(XmlPullParser.START_TAG, ns, "breed")
val breed = readText(parser)
parser.require(XmlPullParser.END_TAG, ns, "breed")
return breed
}
@Throws(XmlPullParserException::class, IOException::class)
private fun readName(parser: XmlPullParser): String {
parser.require(XmlPullParser.START_TAG, ns, "name")
val name = readText(parser)
parser.require(XmlPullParser.END_TAG, ns, "name")
return name
}
@Throws(XmlPullParserException::class, IOException::class)
private fun readText(parser: XmlPullParser): String {
var result = ""
if (parser.next() == XmlPullParser.TEXT) {
result = parser.text
parser.nextTag()
}
return result
}
|
3.6、跳过不感兴趣的标签
解析器需要跳过不感兴趣的标签,下面是解析器的skip方法,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@Throws(XmlPullParserException::class, IOException::class)
private fun skip(parser: XmlPullParser) {
if (parser.eventType != XmlPullParser.START_TAG) {
throw IllegalStateException()
}
var depth = 1
while (depth != 0) {
when (parser.next()) {
XmlPullParser.END_TAG -> depth--
XmlPullParser.START_TAG -> depth++
}
}
}
|
其工作原理如下:
- 如果当前事件不是START_TAG,则会抛出异常。
- 它会使用START_TAG以及直到匹配的END_TAG(含)的所有事件。
- 为确保其在遇到正确的END_TAG时停止,而非在遇到原始 START_TAG之后的首个标签时停止,它会不断追踪嵌套深度。
因此,如果当前元素具有嵌套元素,在解析器使用了原始START_TAG及其匹配的END_TAG之间的所有事件之前,depth的值不会为0。例如,看看解析器如何跳过拥有name这个嵌套元素的 cat元素:
- 第一次经历while循环时,解析器在<cat>之后遇到的下一个标签是<name>的START_TAG。depth的值递增到2。
- 第二次经历while循环时,解析器遇到的下一个标签是 END_TAG,也就是</name>。depth的值递减为1。
- 第三次,也就是最后一次经历while循环时,解析器遇到的下一个标签是END_TAG,也就是。depth的值递减为0,这表明该方法已成功跳过<cat>元素。
3.7、使用XML数据
第一步:把animal.xml文件放到Assets目录下。
第二步:本文使用Databinding,所以需要在app的build.gradle中添加依赖:
1
2
3
4
5
|
android {
dataBinding {
enabled = true
}
}
|
第三步:改造activity_main.xml布局,这里只有一个点击按钮,给按钮绑定点击事件,点击按钮时触发XML的解析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<?xml version="1.0" encoding="utf-8"?>
<layout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools">
<data>
<variable
name="presenter"
type="com.pengmj.androidparsexml.Presenter" />
</data>
<androidx.constraintlayout.widget.ConstraintLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<Button
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:onClick="@{(view)->presenter.onParseXML(view)}"
android:text="解析XML"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toTopOf="parent" />
</androidx.constraintlayout.widget.ConstraintLayout>
</layout>
|
第四步:实现点击事件。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class Presenter {
companion object {
private val tag: String = Presenter::class.java.simpleName
}
fun onParseXML(view: View) {
val inputStream = view.context.assets.open("animal.xml")
val list = AnimalXMLParser().parse(inputStream)
Log.e(tag, list.toString())
}
}
|
第五步:在MainActivity中将Databinding绑定UI层,设置页面点击事件对象。
1
2
3
4
5
6
7
8
|
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
val binding =
DataBindingUtil.setContentView<ActivityMainBinding>(this, R.layout.activity_main)
binding.presenter = Presenter()
}
}
|
本文源码地址: AndroidParseXML